介绍RAG
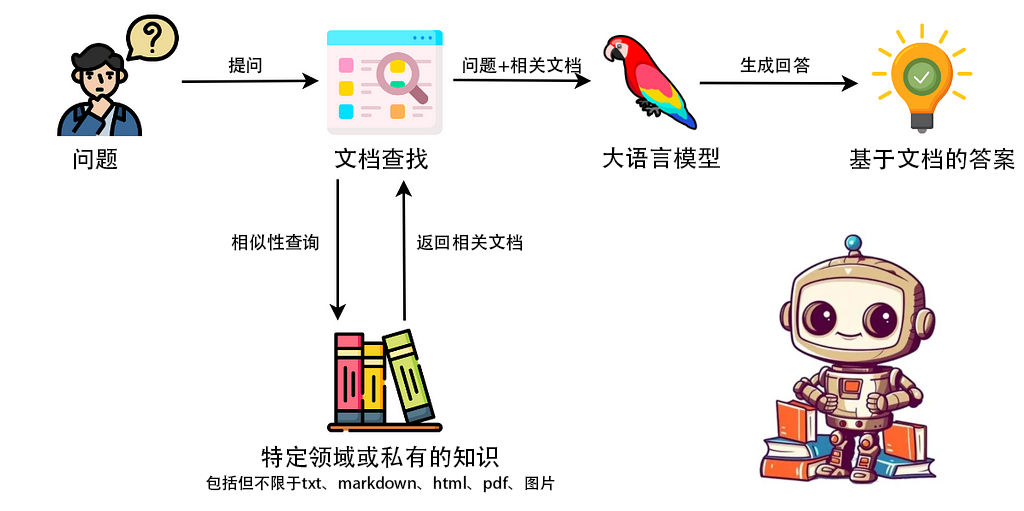
RAG全名为Retrieval Augmented Generation,翻译为检索增强生成。通俗的理解为:给大模型一本精炼 的参考书,让它在回答问题时优先去查参考书,之后拿着查询好的内容再结合它自身的知识整合一下给你答案 。
那大模型训练的时候使用了非常多的文本,很可能已经包含了你所需要的知识,而且它还有更强的整合能力为什么还需要外部知识库呢?
模型存在幻觉 :用过大模型查科研问题的都会碰到过GPT张嘴乱说的情况,看起来它给的引文有模有样,甚至比你想要了解的内容还要,结果一搜压根没有,论文作者呢是能查到,结果一搜出来你是想查人类相关医学文献,它给你整的作者是兽医相关(开玩笑的,其实有时候是化学物理专业的作者)。这就是”幻觉“,从另外一面来看这也是大模型拥有创造力的原因,目前来说是一个技术难题。“幻觉”在很多领域是不能被容忍的,比如法律行业、金融行业、医药行业。
私有知识库 :有的机构、公司、个人拥有私有知识库,不希望这些知识库泄露,用这样的方式就比较好,而且还能随时更新。微调模型当然可以做到,但是每次更新知识库就需要微调模型。
模型上下文有限 :现在都在增加输入给模型的上下文长度,最近刚发布的ChatGlm4最长可以支持1M的上下文,经过评测大海捞针(Needle In A Haystack)的准确性还挺高的。那为什么还需要这种外部知识库呢,直接把知识库全部给它,让他自己去查不行吗?一是运行时间很长,二是token多了花钱比较多,三是推理能力还不够强,复杂知识无法较好呈现,四是很长的上下文得到的结果不一定会好。后面需要技术的更进一步迭代才有可能解决这些问题。
模型专业领域深度不够 :训练的知识可能过时,在专业领域可能深度不够(有时候我觉得还行,难道是我深度不够🤪?)。
参照
本文主要按照这个B站视频进行,主要代码按照视频来。因为我是用的本地模型构建的RAG所以部分代码有所不同:
Up主主要是利用了一个外部网页的知识(民法典),通过联网抓取网页之后提取出其中的文本,经过文本片段提取向量化存储,基于人工询问的问题从库中抓取内容,将其作为上下文和提问一并输入给在线的大模型(OpenAI ChatGPT)进行内容整合输出。这是一个常见的简单的RAG应用,用来入门我觉得不错。
环境搭建
可以看上一篇文章 搭建好ChatGlm3的本地部署。
1 2 conda activate ChatGLM3
打开一下API服务:
之后推荐安装一下jupyter lab,比较方便查看变量和运行过程(安装过程不赘述):
jupyter lab安装步骤 首先安装ipykernal:
1 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jupyterlab ipykernel
增添jupyter lab的运行环境:
1 python -m ipykernel install --user --name ChatGLM3 --display-name "ChatGLM3"
下面的代码可以在jupyter lab中逐步运行,也可以在python脚本中执行。
库导入
还需要安装一些其他的库:
1 2 3 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple langserve pip install -i https://pypi.tuna.tsinghua.edu.cn/simple beautifulsoup4 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple chromadb
导入库:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import bs4from langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.document_loaders import WebBaseLoaderfrom langchain_community.vectorstores import Chromafrom langchain.prompts.prompt import PromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.runnables import RunnablePassthroughfrom fastapi import FastAPIfrom langserve import add_routesfrom sentence_transformers import SentenceTransformerfrom langchain_community.embeddings import HuggingFaceEmbeddingsfrom langchain_community.llms.chatglm3 import ChatGLM3import uvicorn
后面再解释这些库的作用。
数据处理
使用的数据来源于网上,需要先访问到对应网站,再使用网页解析器得到想要的文本,全部的文本一般比较长,需要分片,分片之后转换为向量(embedding),把向量保存到数据库中。
抓取
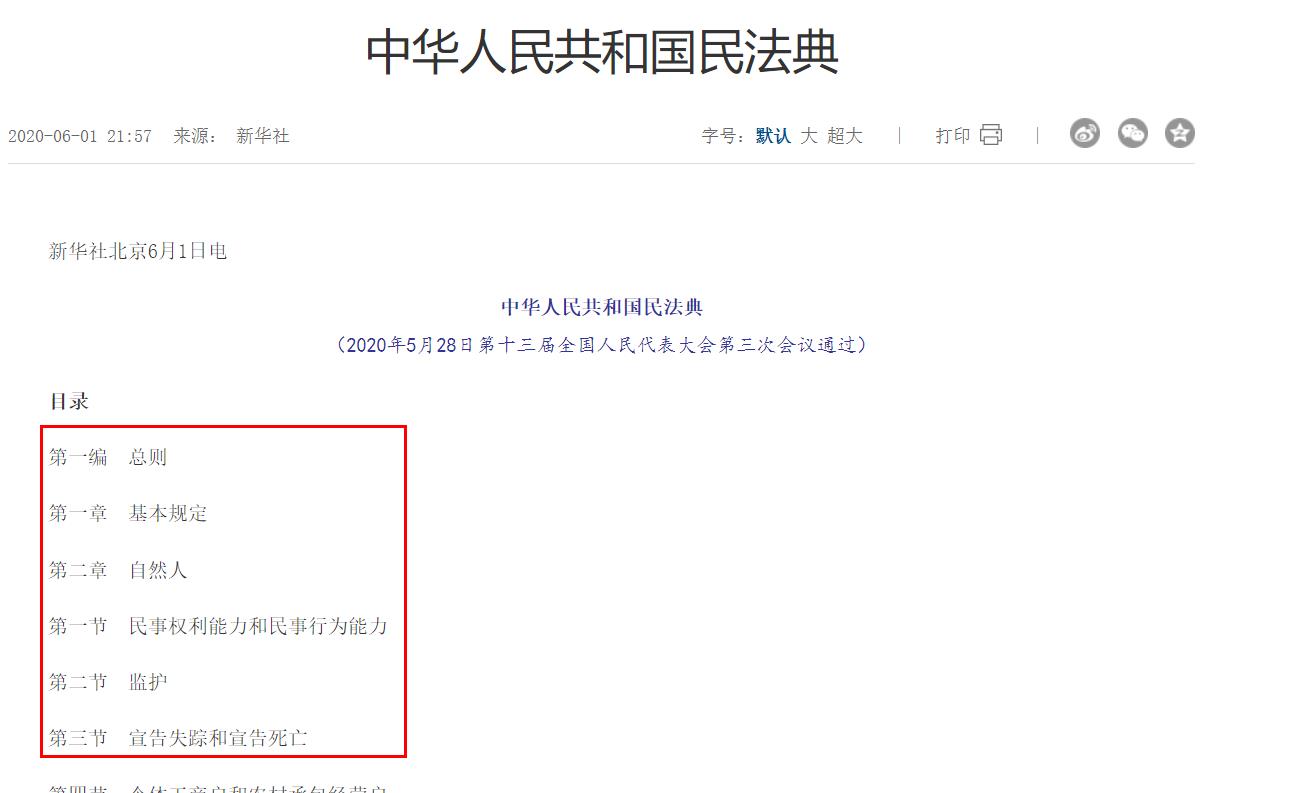
网址为:中华人民共和国民法典 。
需要把网页内的需要的文本抓取出来。
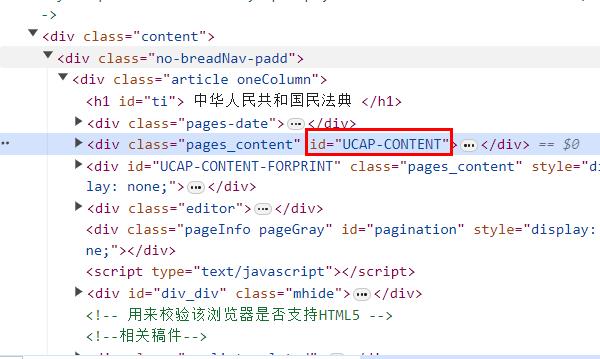
1 2 3 4 5 6 7 def load_web_doc (url, nid ): loader = WebBaseLoader(web_path=url, bs_kwargs=dict (parse_only=bs4.SoupStrainer(id =nid))) docs = loader.load() return docs docs = load_web_doc(url="https://www.gov.cn/xinwen/2020-06/01/content_5516649.htm" , nid="UCAP-CONTENT" )
nid的确定主要是按F12查看网页源码,发现主要的内容块位于UCAP-CONTENT的div下面:
其实可以自己去写一个简单的网页爬虫把网页文本爬下来,这个WebBaseLoader暂时用一下,比较复杂的网站还是要自己写程序去抓取的。
LangChain内置了很多文档解析器,比如这里的网页抓取工具,还有pdf解析工具,txt文本读取工具,markdown读取工具等等。
把文档打印一下看看:
1 2 3 4 5 6 7 8 9 10 11 print (len (docs), type (docs))print (docs[0 ].page_content[0 :100 ])
文本切割
就是把一长段文本划分为一小段一小段的片段,片段之间允许重叠,比如说以20个字符为一个切割块(chunk),不同切割块之间重叠(overlap)5个字符:
1 2 3 4 5 6 原始 :扁担宽,板凳长,扁担想绑在板凳上,板凳不让扁担绑在板凳上,扁担偏要绑在板凳上,板凳偏偏不让扁担绑在那板凳上,到底扁担宽还是板凳长 -------------------------------------------------------------------- 片段1:扁担宽,板凳长,扁担想绑在板凳上,板凳不 片段2: 上,板凳不让扁担绑在板凳上,扁担偏要绑在 片段3: 担偏要绑在板凳上,板凳偏偏不让扁担绑在那 片段4: 扁担绑在那板凳上,到底扁担宽还是板凳长
这个其实非常像我们做生信的对于基因组的处理,一般基因组非常的长就把基因组分割成短的片段,非常短的叫做kmer,长的叫做segment,为了防止前后两个片段的关联丢失,常常会让他们重叠一定的长度。
基因组划分为kmer 基因组划分为kmer,一般overlap等于kmer的长度 - 1:
1 2 3 4 5 Genome: ATGCAGCTACGAT kmer1 : ATGCAGCTAC kmer2 : TGCAGCTACG kmer3 : GCAGCTACGA kmer4 : CAGCTACGAT
将上面网页抓取的文本进行以1000字符为块长度,不同块之间重叠200长度。
1 2 3 4 5 6 def split_docs (docs ): text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000 , chunk_overlap=200 ) splits = text_splitter.split_documents(docs) return splits doc_splits = split_docs(docs)
看了一些博客很多人说这里的参数对于后续结果影响很大,如果想要提升RAG的效果,这里的参数是需要调整的。
打印一下结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 print (len (doc_splits), type (doc_splits))print (doc_splits[0 ].page_content)
划分得到了139个切割块。使用page_content属性访问具体内容。
向量化
在向量化之前,需要定义一个类,原本的langchain的HuggingFaceEmbeddings死活就加载不了,路径明明给对了还仍然要去下载模型文件,搜了一下报错发现老外也有这个问题,我看了一下对应位置的langchain源码,发现很简单,我稍微调整了重写了一下类就可以用了,顺带回答了一下老外的问题#338 ,原来老外也是有小白的啊,应该比我白。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class SentenceTransformerMy (object ): encode_kwargs = dict () multi_process: bool = False """Run encode() on multiple GPUs.""" show_progress: bool = False """Whether to show a progress bar.""" def __init__ (self, model_path, **kwargs ): self.client = SentenceTransformer(model_path, **kwargs) def embed_documents (self, texts ): """Compute doc embeddings using a HuggingFace transformer model. Args: texts: The list of texts to embed. Returns: List of embeddings, one for each text. """ texts = list (map (lambda x: x.replace("\n" , " " ), texts)) if self.multi_process: pool = self.client.start_multi_process_pool() embeddings = self.client.encode_multi_process(texts, pool) sentence_transformers.SentenceTransformer.stop_multi_process_pool(pool) else : embeddings = self.client.encode( texts, show_progress_bar=self.show_progress, **self.encode_kwargs ) return embeddings.tolist() def embed_query (self, text: str ): """Compute query embeddings using a HuggingFace transformer model. Args: text: The text to embed. Returns: Embeddings for the text. """ return self.embed_documents([text])[0 ]
向量化的目的是什么?
这里可以理解为把文档数字化一串数值,也叫做embedding(具体的embedding将会单独写一篇文章介绍),便于计算机处理。
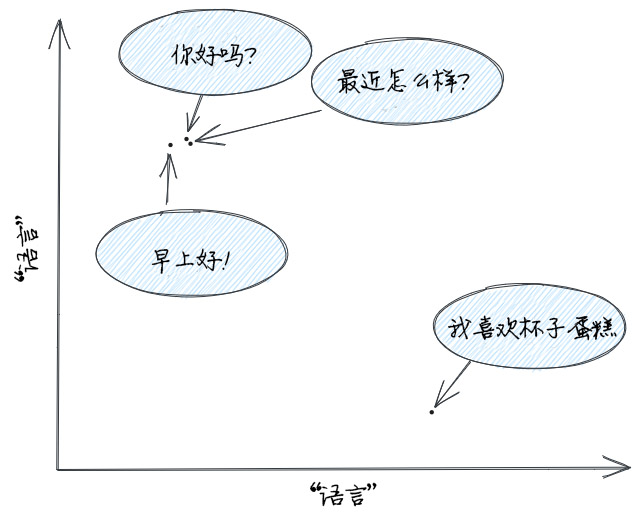
比如:
1 2 3 4 你好吗?: [1.2, 2.5] 最近怎么样?:[1.3, 2.45] 早上好!:[1.1, 2.45] 我喜欢杯子蛋糕:[3.1, 1.4]
将这样转化之后,通过计算这一串数值之间的余弦相似度就可以得到两个句子之间的相似性,假如维度只有2的话,绘制在坐标系上通过位置可以知道句子是相似还是有差异。
所以到这里也就可以知道上面开头流程图里面的相似性查询 是怎样的,比如我问”我醉酒驾驶会怎么样?“,首先把用户输入的内容转换为embedding,然后和数据库里面的文档对应的embedding计算余弦相似度,最后把最为相似的几条文档拿出来就是精炼的参考书 。
也就是说,任何搜索过程都可用于检索 ,你可以不使用这里的langchain定义的Chroma数据库搜索的方式,自己设计一个数据检索方式。任何接受用户输入并返回一些结果的方法都可以。例如,可以尝试查找与用户问题相匹配的文本并将其发送给 LLM,或者用百度搜索该问题并发送最佳结果,顺便说一句,这大致就是 Bing 聊天机器人的工作原理。
保存,就是把不同的切割块转换为的embedding向量保存到Chroma数据库中,具体这个数据库是什么暂时不管,总之就是现在向量化数据保存的其中之一的一个数据库。
1 2 3 4 5 6 7 8 9 10 11 12 embedding_model = SentenceTransformerMy("../models/Xorbits/bge-m3" , device="cuda" ) embedding_model.embed_documents(["你好" , "这里是eternal-bug" ]) def store_docs (docs, embedding_model ): vecs = Chroma.from_documents(documents=docs, embedding=embedding_model, persist_directory="./chroma_db" ) return vecs doc_vectorstore = store_docs(doc_splits, embedding_model)
打开./chroma_db,发现有几个文件:
1 2 3 4 5 6 7 8 9 tree ./chroma_db ./chroma_db/ ├── 508fd8b0-d69b-4c62-aa09-964d96d7c95b │ ├── data_level0.bin │ ├── header.bin │ ├── length.bin │ └── link_lists.bin └── chroma.sqlite3
其中.sqlite3是常见的简单的非登录的数据库文件。除此之外还有几个bin文件不太清楚是做什么的,可能是为了便于快速进行余弦相似度计算的一些东西。
问答
构建问答链
定义模板是非常有讲究的,prompt工程对于模型的影响会很大,这里着重强调了使用以下检索到的上下文来回答问题。如果你不知道答案,就说不知道 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def build_rag_chain (vectorstore ): prompt_template_str = """ 你是民法典问答任务的助手。使用以下检索到的上下文来回答问题。如果你不知道答案,就说不知道。保持答案简洁,答案不要超过三个句子。 问题:{question} 上下文:{context} 答案: """ prompt_template = PromptTemplate.from_template(prompt_template_str) retriever = vectorstore.as_retriever(search_type="similarity" , search_kwargs={"k" : 4 }) llm = ChatGLM3(endpoint_url="http://127.0.0.1:8000/v1/chat/completions" ) def format_docs (docs ): return "\n\n" .join(doc.page_content for doc in docs) rag_chain = ( {"context" : retriever | format_docs, "question" : RunnablePassthrough()} | prompt_template | llm | StrOutputParser() ) return rag_chain
这里的链条要比上一篇文章里面提到的简单链条要复杂很多,里面还用了链条的嵌套。首先是{"context": retriever | format_docs, "question": RunnablePassthrough()},retriever是检索到的文档,经过format_docs函数进行格式化,RunnablePassthrough()是一个在执行的时候再解释输入的函数,它接受了下面的”根据民法典,捐助人反悔如何拿回捐款“的问题,组成好字典之后,给模板prompt_template中的变量进行替换,后续的过程就和之前文章中提到的情况类似了。
测试
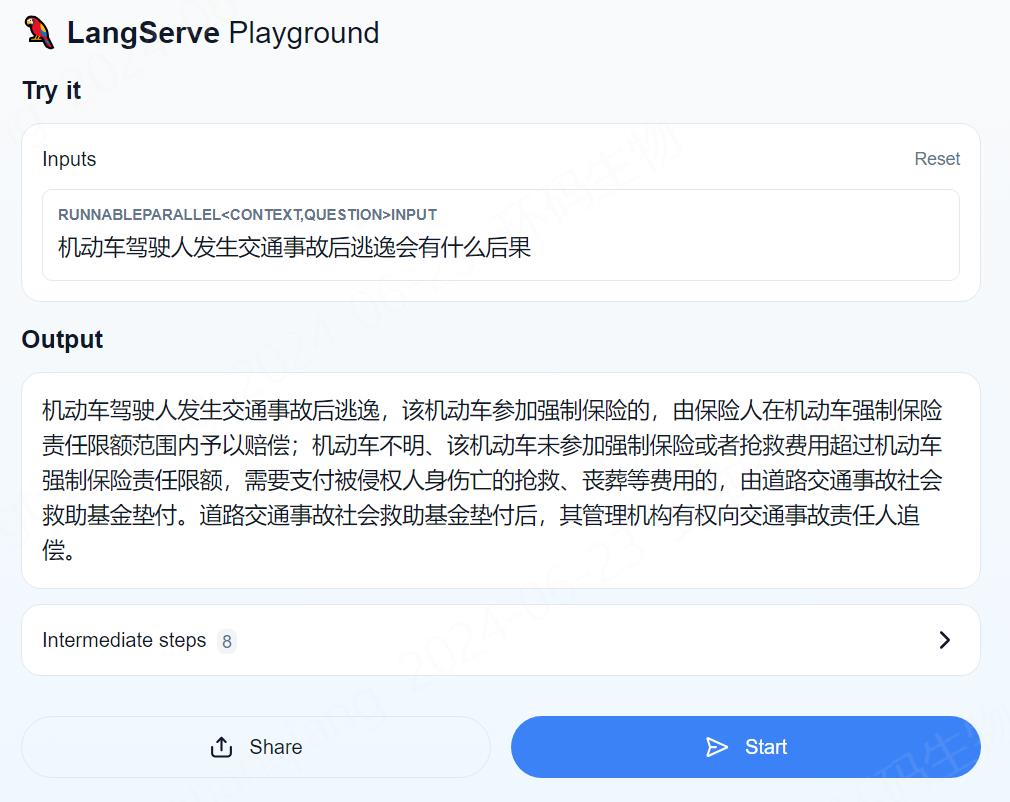
1 2 3 4 5 6 7 8 9 10 11 12 rag_chain = build_rag_chain(doc_vectorstore) print (rag_chain.invoke("根据民法典,捐助人反悔如何拿回捐款" ))
每一次输出的结果会有一些不同,如果需要是有必要要对这个过程做优化的。
再试一下:
1 2 3 print (rag_chain.invoke("根据民法典,不熟读民法典会怎么样" ))
显存大约占据21G,如果中途爆显存不够,把ChatGlm3API重启,这个jupyter lab笔记本Restart kernel。
如果想要查看通过embedding查询到了哪些内容,可以把上面的函数改一下:
1 2 3 4 5 def format_docs (docs ): text = "\n\n" .join(doc.page_content for doc in docs) print (text) return text
比如最开始一个问题”捐助人反悔如何拿回捐款“查询到的内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 依据前款规定应当交付的赠与财产因赠与人故意或者重大过失致使毁损、灭失的,赠与人应当承担赔偿责任。 第六百六十一条 赠与可以附义务。 赠与附义务的,受赠人应当按照约定履行义务。 第六百六十二条 赠与的财产有瑕疵的,赠与人不承担责任。附义务的赠与,赠与的财产有瑕疵的,赠与人在附义务的限度内承担与出卖人相同的责任。 赠与人故意不告知瑕疵或者保证无瑕疵,造成受赠人损失的,应当承担赔偿责任。 第六百六十三条 受赠人有下列情形之一的,赠与人可以撤销赠与: (一)严重侵害赠与人或者赠与人近亲属的合法权益; (二)对赠与人有扶养义务而不履行; (三)不履行赠与合同约定的义务。 赠与人的撤销权,自知道或者应当知道撤销事由之日起一年内行使。 第六百六十四条 因受赠人的违法行为致使赠与人死亡或者丧失民事行为能力的,赠与人的继承人或者法定代理人可以撤销赠与。 赠与人的继承人或者法定代理人的撤销权,自知道或者应当知道撤销事由之日起六个月内行使。 第六百六十五条 撤销权人撤销赠与的,可以向受赠人请求返还赠与的财产。 第六百六十六条 赠与人的经济状况显著恶化,严重影响其生产经营或者家庭生活的,可以不再履行赠与义务。 第十二章 借款合同 ...
还是比较相关的,因为这个是固定流程不会出现变数。
网页应用
整体上的逻辑不变,就是用FastAPI构建了一个网页UI:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def create_app (rag_chain ): app = FastAPI( title = "中国民法典助手" , version=0.1 ) add_routes( app, rag_chain, path="/civil_law_ai" ) return app app = create_app(rag_chain) uvicorn.run(app, host="0.0.0.0" , port=10004 )
这个在jupyter lab中不能正常运行,需要把上面所有的代码都放在脚本中然后在命令行运行,命令行出现下面的情况表示成功:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 USER_AGENT environment variable not set, consider setting it to identify your requests. INFO: Started server process [3809065] INFO: Waiting for application startup. __ ___ .__ __. _______ _______. _______ .______ ____ ____ _______ | | / \ | \ | | / _____| / || ____|| _ \ \ \ / / | ____| | | / ^ \ | \| | | | __ | (----`| |__ | |_) | \ \/ / | |__ | | / /_\ \ | . ` | | | |_ | \ \ | __| | / \ / | __| | `----./ _____ \ | |\ | | |__| | .----) | | |____ | |\ \----. \ / | |____ |_______/__/ \__\ |__| \__| \______| |_______/ |_______|| _| `._____| \__/ |_______| LANGSERVE: Playground for chain "/civil_law_ai/" is live at: LANGSERVE: │ LANGSERVE: └──> /civil_law_ai/playground/ LANGSERVE: LANGSERVE: See all available routes at /docs/
在浏览器中访问:http://服务器地址:10004/civil_law_ai/playground/,其中civil_law_ai就是我们自己起的名字。
测试
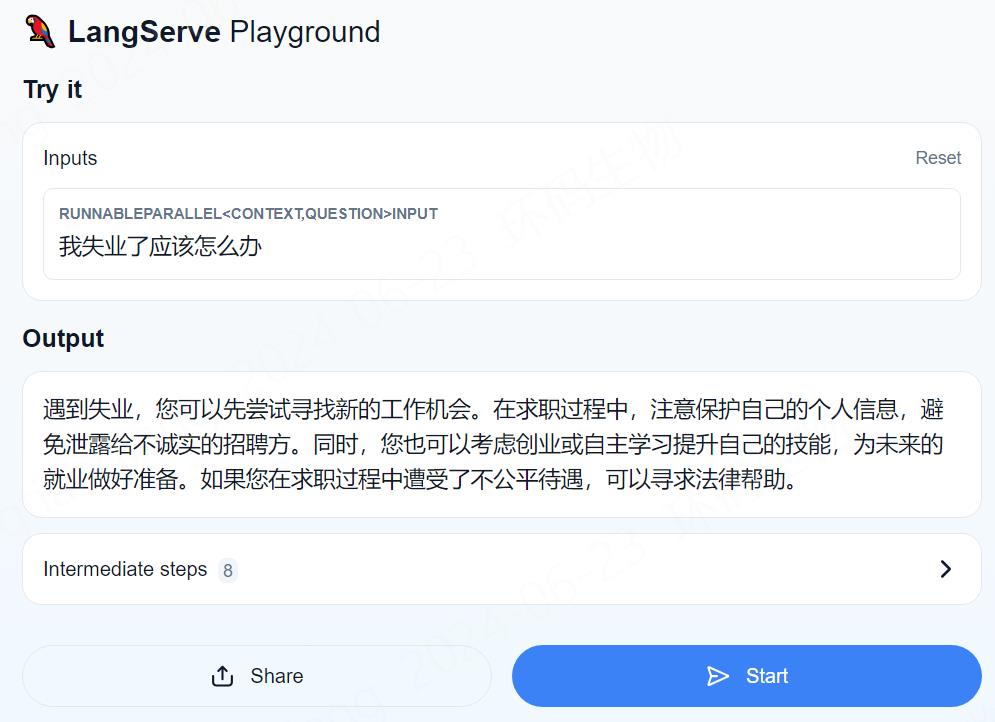
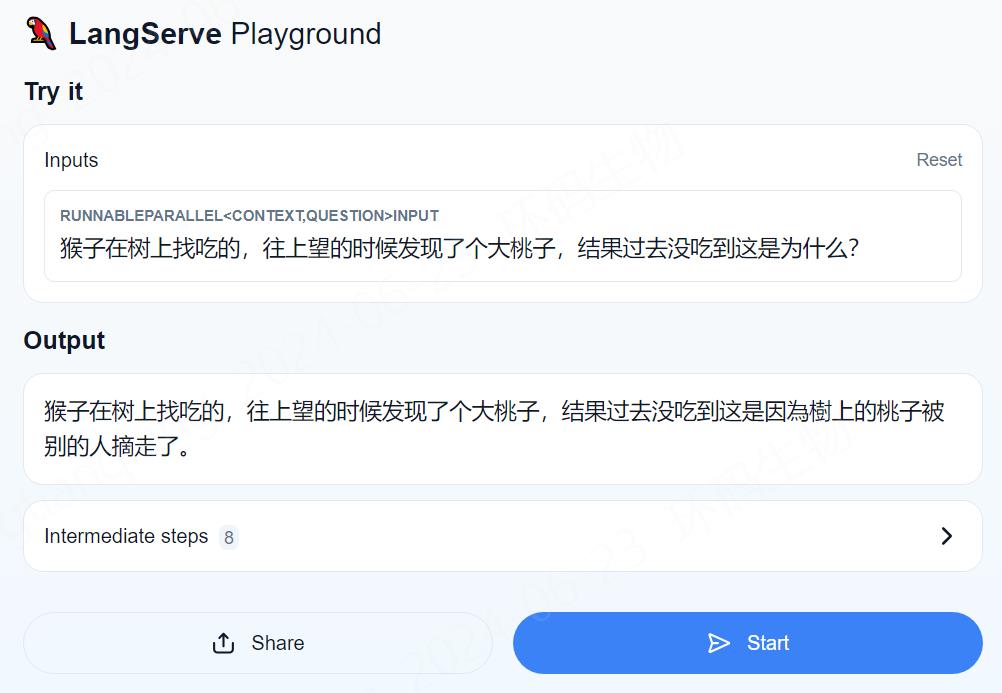
1.正经问题 2.失业问题 3.脑筋急转弯 4.常识问题
还行,经检查和原文一摸一样
原本以为民法典有失业的内容,其实没有,这里是模型根据自己的知识回答的。
没想到原本严肃的律师也还有天真的一面!
成功被我带跑偏,你这律师是不是有点讨好型人格。
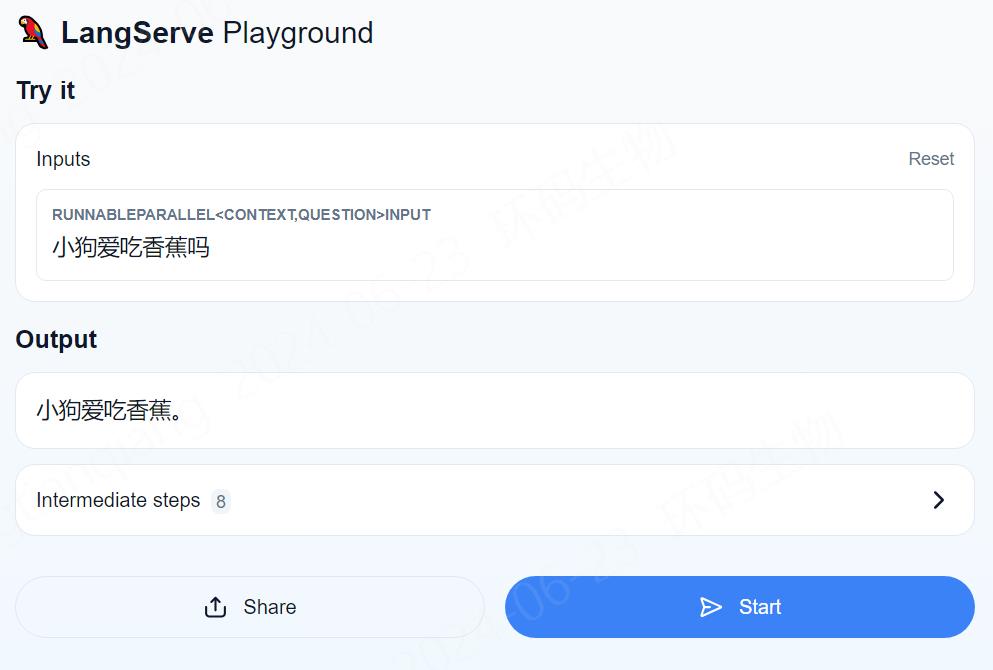
经测试和视频中的结果有点偏差,特别是最后三个和民法典无关的问题,”狗子喜欢吃香蕉吗?“这个问题视频中直接回答的是”不知道“,而且按照我给与的提示词也不能回答其他的内容。这里就和预期不相符,看来ChatGlm3和ChatGPT还是有一些差距的。
你的浏览器不支持
我写完文章后,深思了许久…,这不是可以考虑去当个辩护律师啊!拿着我这个工具,跑到法庭往那儿一站,当着审判长的面儿,桌子一拍,手一指:“一斤鸭梨!”
结果可想而知🤔,拿这个工具做出回答应该比出示律师徽章好不到哪儿去。
参考
How do domain-specific chatbots work? An Overview of Retrieval Augmented Generation (RAG)
图片更改自:Knowledge Graphs & LLMs: Fine-Tuning vs. Retrieval-Augmented Generation Retrieval Augmented Generation using Langchain



 微信打赏
微信打赏