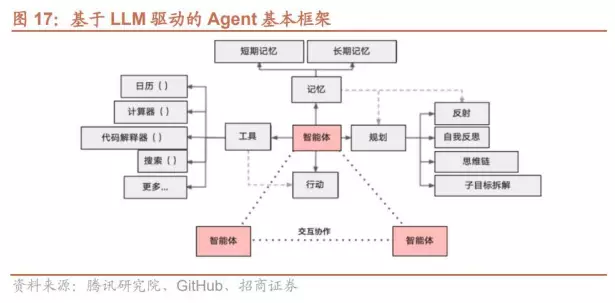
Agent是什么
Agent 是具备通过独立思考、调用工具去逐步完成给定目标的智能工具。国内举例子最常见的就是点外卖Agent🤣:告诉 Agent 帮忙下单一份炸鸡的外卖,它就可以根据你的习惯和消费水平直接调用 APP 筛选合适的外卖,再调用支付程序下单支付,无需人类去指定每一步的操作。这与之前的比如小度小度关灯啊、放音乐啊、关窗帘的工具不同,Agent涉及到更为复杂的过程。
关于Agent网上有铺天盖地的新闻我就不多说了。其中工具调用(function call)就是非常关键的一环。
大语言模型算算术常常出错,让它去用一个计算器是不是很合理?
计算器
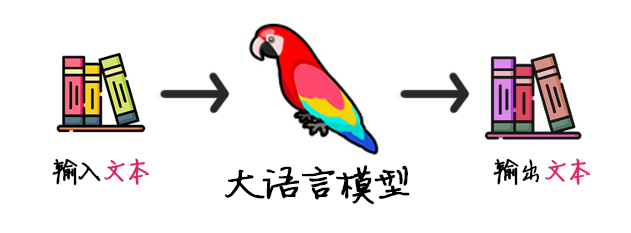
在文章最开头,先来问一个问题:大语言模型已知只能接受文本而且只能输出文本,怎么样让它去用计算器呢?
如果按照python代码函数调用的方式,为什么输出了文本能去调用函数(function call)呢?就像通感了一样:
微风过处,送来缕缕清香,仿佛远处高楼上渺茫的歌声似的。
又或者说让我不动手脚只动嘴说话去控制计算器一样(🤔如果真的能打嘴炮利用空气波也许能按动计算器吧😏)。
文本是什么
在ChatGPT出来后的一段时间内,我一直用来它聊天摸鱼、顺带把活儿干了感觉挺好,它是一个很聪明的,有逻辑的”对话工具“,对我来说仅此而已。然而就在它掀起人工智能新浪潮的背后,更为智能的机器人项目也在萌生,比如特斯拉的Optimus 、OpenAI的Figure01 ,这些机器人可以很快理解人的指令并执行动作,比如拿起桌子上的苹果,而且具有学习能力具有计划,有人说这么快的响应速度很可能不仅仅是因为大语言模型,具体细节我不是太清楚就不多说了。我想强调的是当我看到关于它们的新闻时不太能将”对话工具“和“实体机械臂”之间关联起来,如果是做一个没有实体的、类似于电影《Her》里面情感聊天机器人,这我是能理解的。中间一段时间没有深入了解,也就不了了之了,后来在B站偶然看到一个现在看起来很普通的评论说:“大语言模型可以返回json”,那会儿我瞬间就想明白了,文本不仅仅只是我们现在平常生活中说的这种语言,语言能够承载信息,对信息进行进一步的处理就能完成上面的事。
从此我开始意识到之前对“文本”的定义过于狭隘,实际上我们人很多的事情都可以通过以文本的形式写出来:比如用诗歌表达自己的所见所闻所感;用记叙文记录旅游的过程;用数学公式记录思维逻辑推导;编写代码自动化批量下载文件;写下制作沙瓶子画所需要的步骤等等。这里面的诗歌 、记叙文 、数学公式 、代码 、步骤 都是文本 。更加详细点,文本还包括:json 、markdown 、docx 、excel 、ppt 、pdf 里面的文字内容。最需要强调的是json,因为这是不同程序之间交流信息最为常见的格式 ,特别是网站API,这也是前后端经常吵架的聚焦点😓(前端和后端可能会因为数据格式、字段约定、API设计等问题互怼),上一篇文章 中提到的OpenAI的标准就是传输的json。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 { "北京" : { "坐标" : [ "116E" , "40N" ] , "别名" : [ "北平" 、"燕京" 、"蓟" 、"幽州" ] } , "上海" : { "坐标" : [ "121E" , "31N" ] , "别名" : [ "申城" , "魔都" , "上海滩" ] } , "南京" : { "坐标" : [ "118E" , "31N" ] , "别名" : [ "金陵" , "建康" , "应天" , "天京" , "徽京" , "江苏人的萨拉热窝" , "台湾人的耶路撒冷" , "安徽人的柯尼斯堡" , "鸭子们的奥斯维辛" ] } , ... }
这就是json,一种有结构的、规则的、信息密集的格式,因为本身数据的组织方式就携带了信息,这个比用一段文字去描述会更加有效,也更加方便程序去读取。除了json之外也还有其他很多的格式。
题外话
据说中文的信息密度要比外文高很多,也就是压缩率很高,成语被人说是压缩包,举个例子,“杯水车薪”,中国人脑袋自带极为优异的解压器,而老外必须再装个解压效率一般的解压器。再比如说为什么弹幕文化我们亚洲的发展更加好,因为信息压缩比例高,在相同长度的显示下,中文、日文等能够包含更多信息,而携带相同信息的英文就需要更长的显示,弹幕本来就是实时交流的,不能过长,欧美都是在侧面的的滚动聊天记录,这和弹幕有着天壤之别。
但是,与直觉相反,相同的请求,用中文消耗的token竟然多于英文,暂时没有想明白为什么。
世界上信息熵最大的语言是汉语吗? Which reads faster, Chinese or English?
大语言模型可以输入和输出有格式的,有规则的 文本之后,那就能回答说我具体想要做什么呢,以及怎么做,有哪些细节,比如说问它一下应该怎么做一道番茄炒蛋:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 首先eternal-bug你要去菜市场买或者自家小院准备 菜单: - 番茄 - 数量:2个 - 色泽:鲜红色 - 鸡蛋 - 数量:2个 - 色泽:微黄色泛红 步骤: - 取两三个鸡蛋,打匀,放上少许盐,备用 - 番茄切片放在盘子备用 - 起锅烧油,油不能太热 - 倒入混匀的鸡蛋翻炒 - 炒自略微发黄的取出放在盘子里备用 - 烧油,油不能太热 - 倒入番茄番茄 - 倒入超过的鸡蛋翻炒 - 出锅
按照这样有条理的“文本”,通过大语言模型来完成工具调用也就有可能了:大语言模型就是负责想,负责计划,负责使唤就行了。
你可能想到点儿什么…,这不是我老公吗,这不是我老婆吗,这不是我女朋友吗?
“eternal-bug ,我不想动,你去帮我把充电器拿来。算了算了,充电器线不够,找找充电宝!”eternal-bug 你成天没事儿做是吧,还打王者荣耀,做饭去!家里都揭不开锅了!打打打就知道打游戏,这一天天的!”
😏你女朋友还是你的,我只是举个例子,希望以后的人工智能不要这样🤪。
具体是怎么实现的呢?在此之前我还得像老太婆一样唠叨一句:大语言模型的输入和输出只能是文本 。具体说是文本的token id:
1 文本 -> token ids -> 大语言模型 -> token ids -> 文本
抽丝剥茧
如果本地没有部署ChatGLM3模型,可以先按照我上一篇文章 进行本地部署。
ChatGLM3这个项目比较贴心里面有很多代码,在执行项目的tools_using_demo文件夹下,有一个cli_demo_tool.py的代码,里面写了关于基本的function call的形式。其它的代码暂时忽略,主要关注第119行的:
1 response, history = model.chat(tokenizer, query, history=history, role=role)
可以以此来确定进行function call需要输入哪些东西:
tokenizer:用来将句子转换为编号的模型。query:输入的问题或者信息。history:历史聊天记录。role:目前扮演的角色。
token
简单的说就是一句话里面的最小单元,比如中文里面的单个文字,通过给每一个文字和标点给上一个编号就叫做token id,方便计算机处理,tokenizer就是用来将文字进行转换的模型,比如(这里的token id是我瞎掰的,意思就是这个意思):
1 2 3 4 我 -> 10 喜 -> 234 欢 -> 546 你 -> 11
chat方法不是最为底层的方法,通常是基于模型生成的基础上自定义的功能,需要再进一步查看chat代码里面是什么,transformers库提供的是基本 的模型和分词器接口,用于文本生成、分类等任务,其中最为基本的预测方法来源于transformers.modeling_utils.PreTrainedModel叫做generate。
在下载的模型权重ZhipuAI/chatglm3-6b文件夹里面有一个modeling_chatglm.py和tokenization_chatglm.py文件,它里面有模型chat方法和tokenizer字符串拼接的方法。这就是了解到底层原理的关键。(这样的脚本文件并不出现在早期不支持工具调用的ZhipuAI/chatglm-6b模型中)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def chat (self, tokenizer, query: str , history: List [Dict ] = None , role: str = "user" , max_length: int = 8192 , num_beams=1 , do_sample=True , top_p=0.8 , temperature=0.8 , logits_processor=None , **kwargs ): if history is None : history = [] if logits_processor is None : logits_processor = LogitsProcessorList() logits_processor.append(InvalidScoreLogitsProcessor()) gen_kwargs = {"max_length" : max_length, "num_beams" : num_beams, "do_sample" : do_sample, "top_p" : top_p, "temperature" : temperature, "logits_processor" : logits_processor, **kwargs} inputs = tokenizer.build_chat_input(query, history=history, role=role) inputs = inputs.to(self.device) eos_token_id = [tokenizer.eos_token_id, tokenizer.get_command("<|user|>" ), tokenizer.get_command("<|observation|>" )] outputs = self.generate(**inputs, **gen_kwargs, eos_token_id=eos_token_id) outputs = outputs.tolist()[0 ][len (inputs["input_ids" ][0 ]):-1 ] response = tokenizer.decode(outputs) history.append({"role" : role, "content" : query}) response, history = self.process_response(response, history) return response, history
这里进一步看build_chat_input()方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def build_chat_input (self, query, history=None , role="user" ): if history is None : history = [] input_ids = [] for item in history: content = item["content" ] if item["role" ] == "system" and "tools" in item: content = content + "\n" + json.dumps(item["tools" ], indent=4 , ensure_ascii=False ) input_ids.extend(self.build_single_message(item["role" ], item.get("metadata" , "" ), content)) input_ids.extend(self.build_single_message(role, "" , query)) input_ids.extend([self.get_command("<|assistant|>" )]) return self.batch_encode_plus([input_ids], return_tensors="pt" , is_split_into_words=True )
这里主要做了几件事情:(1) 将history列表中的信息使用换行符\n把字符串拼接起来,在role是system的时候单独处理字符串因为(system指定的提示词一定是非常关键的和格式特殊的)。(2) 将现在最新的role和query字符串拼接起来。(3) 最后添加一个<|assistant|>的标记。(4) batch_encode_plus是transformers的内置方法,就是把数据转换为特定格式的数据,这不是这里的重点。
注意这里出现了个特殊标记<|assistant|>,除此之外,还有几个标记,在这个python文件中,一个名叫SPTokenizer的类下面,有一个列表:
1 2 3 special_tokens = ["[MASK]" , "[gMASK]" , "[sMASK]" , "sop" , "eop" , "<|system|>" , "<|user|>" , "<|assistant|>" , "<|observation|>" ]
前面几个标记是大语言模型常见的,比如[MASK]通常用于掩码语言模型(如 BERT,Transformer)中的掩码预测任务;sop通常表示句子的开头(start of passage)等等。
主要是最后4个<|system|>、<|user|>、<|assistant|>、<|observation|>。这揭示了大语言模型仅靠输入文本就能回复有规律的答案的秘密。这是一种特殊标记,看英文单词也能看出来:
1 2 3 4 <|system|> 系统 用来标记系统指令,一般在最开始就定义好的,比如说你现在需要扮演一名律师。 <|user|> 用户 标记用户说的话。 <|assistant|> 助理 标记模型回复的信息 <|observation|> 观测 标记外部call function返回的数据。
按照上面的build_chat_input的代码,好像在不停的拼接和role相关的角色和文本内容,这些角色的标记只有上面框中的四种,这是用来告诉模型看到这个标记就需要做不一样的动作。
相当于在训练一只狗子一样,在他的记忆中存在了这样的印记,坐下,过来,握手,吃饭:
这里的<|assistant|>这样的特殊标记就是模型被训练之后留在它记忆中的印记。
需要注意的是上面的字符串拼接并不是一次性先拼接好,类似于
1 2 3 4 5 <|system|> 你现在需要扮演我的女友 <|user|> 你喜欢我吗?
再一次性转换为token id(❌)。
而是特殊标记需要单独转换为相应token id(✅):
token ids =[ <|system|>的token id , 你现在需要扮演我的女友的token id, <|user|>的token id, 你喜欢我吗?的token id]。
如果先把所有的字符串拼接好了再一次性转换为token id,可能会导致<|system|>不作为整体进行token转换,而是比如拆分为<,|,system,|,>字符分别转换。这样特殊标记就失效了,模型很可能会做出完全不同的回应。
特殊标记是为了让模型对内容进行区分。在官方文档中,有说明工具调用的过程(文档写的叫做思维链)和这些特殊标记的关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <|system|> 给模型的指令和关于函数的描述 <|user|> 提出的问题 <|assistant|> 思考应该做什么 <|assistant|> 调用工具以及工具的参数 toolname(参数) <|observation|> 外部的function返回的结果 <|assistant|> 回复用户最后function执行的结果(如果没有返回结果模型并不会回复用户)
和工具调用最为关键的是<|system|>标记后接上的函数描述,那应该怎么写函数的描述才能让模型告诉说你现在这个问题要调用哪个函数呢?这些函数有哪些参数需要设置呢?
是要定义一个特殊的文本,类似于下面的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 {'content' : 'Answer the following questions as best as you can. You have access to the following tools:' , 'role' : 'system' , 'tools' : [{'description' : '查询对应城市的天气' , 'name' : 'get_weather' , 'parameters' : {'properties' : {'city' : {'description' : '需要查询天气的城市' }}, 'required' : [], 'type' : 'object' }}, {'description' : '生成随机数' , 'name' : 'generate_random_number' , 'parameters' : {'properties' : {'min_v' : {'description' : '最小值' }, 'max_v' : {'description' : '最大值' }}, 'required' : [], 'type' : 'object' }} ] }
这是官方给出的一个示例就是json格式。首先是给模型一个指令说:「你要尽可能的回答问题,你可以去用下面这些工具」,第二部分就是关于函数的描述。这里role指定为system。
关于tools的定义,一个列表就是一个函数的具体描述,里面包含很多键值对,比如查看天气的函数get_weather:
description:该函数的描述。(模型通过对用户的提问的理解来判断是不是应该调用这个函数)name:函数的名称。parameters:函数具体参数的描述。
type:参数类型。required:哪些参数是需要要填的。properties:具体的参数说明
city:参数的名称。{'description': '需要查询天气的城市'}:这个参数的描述。(模型通过对用户的提问的理解来确定有没有设置这个参数)
除此之外,还有一些其他的设置,后续再给出。之所以要这么写,因为这是目前OpenAI的标准,模型就是这么训练的,后续使用它对于这种格式和组织方式识别和理解准确性更高。
下面写一下查询天气和生成随机数这两个函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import randomimport requestsdef get_weather (city ): if not isinstance (city_name, str ): raise TypeError("City name must be a string" ) key_selection = {"current_condition" : ["temp_C" , "FeelsLikeC" , "humidity" , "weatherDesc" , "observation_time" ]} try : resp = requests.get(f"https://wttr.in/{city_name} ?format=j1" ) resp.raise_for_status() resp = resp.json() ret = {k: {_v: resp[k][0 ][_v] for _v in v} for k, v in key_selection.items()} except : ret = "Error encountered while fetching weather data!\n" return str (ret) def generate_random_number (min_v, max_v ): if not isinstance (min_v, (int , float )): raise TypeError("min_v must be an integer" ) if not isinstance (max_v, (int , float )): raise TypeError("max_v must be an integer" ) return str (random.randint(min_v, max_v))
需要注意是:
(1) ChatGLM3返回的只是文本,后面调用函数是通过文本解析出来,参数的类型或者范围有可能不对,所以需要对参数类型或者范围进行判断以免导致函数执行失效。(2) 返回的结果转换为字符串类型,因为后续模型需要转换为token id。
小技巧
其实函数不一定需要真正的执行,在测试阶段,可以写一个伪函数(dummy function),假装执行了函数:
1 2 3 def generate_random_number (min_v, max_v ): return 1
这个技巧在一些比较花费时间的函数上是很有用的。
有了函数和函数描述后,就给模型装只手臂🦾,它分析问题下发指令让机械手去执行任务(执行函数)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 function_mapping = { 'get_weather' : get_weather, 'generate_random_number' : generate_random_number, } def function_call (response ): function_name = response['name' ] parameters = response['parameters' ] if function_name in function_mapping: result = function_mapping[function_name](**parameters) return result else : raise ("Function '{function_name}' not found." .format (function_name))
这里所有的代码已经有了,参照官方给的代码,完整的代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 import osimport jsonimport randomimport requestsfrom transformers import AutoTokenizer, AutoModeldef get_weather (city ): if not isinstance (city, str ): raise TypeError("City name must be a string" ) key_selection = {"current_condition" : ["temp_C" , "FeelsLikeC" , "humidity" , "weatherDesc" , "observation_time" ]} try : resp = requests.get(f"https://wttr.in/{city} ?format=j1" ) resp.raise_for_status() resp = resp.json() ret = {k: {_v: resp[k][0 ][_v] for _v in v} for k, v in key_selection.items()} except : ret = "Error encountered while fetching weather data!\n" return str (ret) def generate_random_number (min_v, max_v ): if not isinstance (min_v, (int , float )): raise TypeError("min_v must be an integer" ) if not isinstance (max_v, (int , float )): raise TypeError("max_v must be an integer" ) return str (random.randint(min_v, max_v)) system_tool_description = { 'content' : 'Answer the following questions as best as you can. You have access to the following tools:' , 'role' : 'system' , 'tools' : [{'description' : '查询对应城市的天气' , 'name' : 'get_weather' , 'parameters' : {'properties' : {'city' : {'description' : '需要查询天气的城市' }}, 'required' : [], 'type' : 'object' }}, {'description' : '生成随机数' , 'name' : 'generate_random_number' , 'parameters' : {'properties' : {'min_v' : {'description' : '最小值' }, 'max_v' : {'description' : '最大值' }}, 'required' : [], 'type' : 'object' }} ] } function_mapping = { 'get_weather' : get_weather, 'generate_random_number' : generate_random_number, } def function_call (response ): function_name = response['name' ] parameters = response['parameters' ] if function_name in function_mapping: result = function_mapping[function_name](**parameters) return result else : raise ("Function '{function_name}' not found." .format (function_name)) if __name__ == "__main__" : MODEL_PATH = os.environ.get("MODEL_PATH" ) TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH" , MODEL_PATH) model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True , device_map="auto" ).eval () tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True ) past_key_values, history = None , [system_tool_description] query = input ("\n用户:" ) print ("\nChatGLM:" , end="" ) response, history = model.chat(tokenizer, query, history=history, role="user" ) print (response, end="" , flush=True ) result = function_call(response) response, history = model.chat(tokenizer, result, history=history, role="observation" ) print ("\nChatGLM:" , end="" ) print (response, end="" , flush=True ) print ()
把代码保存为文件比如test_tool.py执行代码(在之前需要export MODEL_PATH=...),得到的结果为:
1 2 3 4 5 用户:上海天气 ChatGLM:{'name': 'get_weather', 'parameters': {'city': '上海'}} ChatGLM:根据您的查询,我已经获取了上海的天气信息。目前上海的天气状况为:晴朗,当前温度为32摄氏度,湿度为63%,体感温度为34摄氏度。这些信息是从我们可信赖的天气API中获取的,并且这些数据是在09:06 AM时更新的。
也可以问问生成随机数,比如说生成1-20的随机数。
到这里其实应该也明白了,原来工具调用也是一种特殊的prompt 啊!
逐步执行
其他代码不变,额外增加几个函数,将__main__:中的代码做了更改,这里不使用模型自己定义的chat方法,而是使用更为底层的generate方法,因为需要做特殊标记和文本的token id的组合写的比较啰嗦。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 from copy import deepcopyfrom transformers.generation.logits_process import LogitsProcessorfrom transformers.generation.utils import LogitsProcessorListclass InvalidScoreLogitsProcessor (LogitsProcessor ): def __call__ (self, input_ids: torch.LongTensor, scores: torch.FloatTensor ) -> torch.FloatTensor: if torch.isnan(scores).any () or torch.isinf(scores).any (): scores.zero_() scores[..., 5 ] = 5e4 return scores def parse_tool_call (response, history ): history = deepcopy(history) response = response.split("<|assistant|>" )[-1 ] metadata, content = response.split("\n" , maxsplit=1 ) history.append({"role" : "assistant" , "metadata" : metadata, "content" : content}) if history[0 ]["role" ] == "system" and "tools" in history[0 ]: content = "\n" .join(content.split("\n" )[1 :-1 ]) def tool_call (**kwargs ): return kwargs parameters = eval (content) content = {"name" : metadata.strip(), "parameters" : parameters} else : content = {"name" : metadata.strip(), "content" : content} return content, history if __name__ == "__main__" : MODEL_PATH = os.environ.get("MODEL_PATH" ) TOKENIZER_PATH = os.environ.get("TOKENIZER_PATH" , MODEL_PATH) tokenizer = AutoTokenizer.from_pretrained(TOKENIZER_PATH, trust_remote_code=True ) model = AutoModel.from_pretrained(MODEL_PATH, trust_remote_code=True , device_map="auto" ).eval () logits_processor = LogitsProcessorList() logits_processor.append(InvalidScoreLogitsProcessor()) gen_kwargs = {"max_length" : 8192 , "num_beams" : 1 , "do_sample" : True , "top_p" : 0.8 , "temperature" : 0.8 , "logits_processor" : logits_processor} query = input ("\n用户:" ) print ("\nChatGLM:" , end="" ) input_token_ids = list () history = [system_tool_description] for item in history: content = item["content" ] if item["role" ] == "system" and "tools" in item: content = content + "\n" + json.dumps(item["tools" ], indent=4 , ensure_ascii=False ) input_token_ids.append(tokenizer.get_command("<|{role}|>" .format (role=item["role" ]))) input_token_ids.extend(tokenizer.encode(content)) input_token_ids.append(tokenizer.get_command("<|{role}|>" .format (role="user" ))) input_token_ids.extend(tokenizer.encode(query)) input_token_ids.append(tokenizer.get_command("<|{role}|>" .format (role="assistant" ))) inputs = tokenizer.batch_encode_plus([input_token_ids], return_tensors="pt" , is_split_into_words=True ) inputs = inputs.to(model.device) eos_token_id = [tokenizer.eos_token_id, tokenizer.get_command("<|user|>" ), tokenizer.get_command("<|observation|>" )] outputs = model.generate(**inputs, **gen_kwargs, eos_token_id=eos_token_id) outputs = outputs.tolist()[0 ][len (inputs["input_ids" ][0 ]):-1 ] response = tokenizer.decode(outputs) print ("====> " , response) response, history = parse_tool_call(response, history) result = function_call(response) print ("====> " , result) input_token_ids = list () for item in history: content = item["content" ] if item["role" ] == "system" and "tools" in item: content = content + "\n" + json.dumps(item["tools" ], indent=4 , ensure_ascii=False ) input_token_ids.append(tokenizer.get_command("<|{role}|>" .format (role=item["role" ]))) input_token_ids.extend(tokenizer.encode(content)) input_token_ids.append(tokenizer.get_command("<|{role}|>" .format (role="observation" ))) input_token_ids.extend(tokenizer.encode(result)) input_token_ids.append(tokenizer.get_command("<|{role}|>" .format (role="assistant" ))) inputs = tokenizer.batch_encode_plus([input_token_ids], return_tensors="pt" , is_split_into_words=True ) inputs = inputs.to(model.device) eos_token_id = [tokenizer.eos_token_id, tokenizer.get_command("<|user|>" ), tokenizer.get_command("<|observation|>" )] outputs = model.generate(**inputs, **gen_kwargs, eos_token_id=eos_token_id) outputs = outputs.tolist()[0 ][len (inputs["input_ids" ][0 ]):-1 ] response = tokenizer.decode(outputs) print ("\nChatGLM:" , end="" ) print (response, end="" , flush=True ) print ()
这里思维链为:
1 2 3 4 5 6 7 8 9 10 <|system|> Answer the following questions as best as you can. You have access to the following tools: [{'description': '查询对应城市的天气', 'name': 'get_weather', ... ] <|user|> 上海天气 <|assistant|>
模型思考之后得到需要调用的函数以及对应的参数:
1 2 <|assistant|> get_weather tool_call(city='上海')
执行函数之后,模型将结果进行整合:
1 2 3 4 5 <|observation|> {'current_condition': {'temp_C': '30', 'FeelsLikeC': '42', 'humidity': '79', 'weatherDesc': [{'value': 'Sunny'}], 'observation_time': '03:24 AM'}} <|assistant|> 您好,根据您的查询,我已经帮您获取到了上海的天气信息。目前上海的天气状况是晴朗,温度为30摄氏度,湿度为79%,体感温度为42摄氏度。这个天气状况是从API中获取到的,并且API的观测时间是今天早上3点24分。
简化函数描述定义
在composite_demo文件夹下tool_registry.py,有一个比较方便的对函数进行注册的装饰器register_tool,不用自己去详细去写json去描述函数和参数,只需要在事先把注释写好:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @register_tool def get_weather ( city_name: Annotated[str , '城市的名称' , True ], str : """ 获取对应城市的天气 """ if not isinstance (city_name, str ): raise TypeError("City name must be a string" ) key_selection = { "current_condition" : ["temp_C" , "FeelsLikeC" , "humidity" , "weatherDesc" , "observation_time" ], } import requests try : resp = requests.get(f"https://wttr.in/{city_name} ?format=j1" ) resp.raise_for_status() resp = resp.json() ret = {k: {_v: resp[k][0 ][_v] for _v in v} for k, v in key_selection.items()} except : import traceback ret = "Error encountered while fetching weather data!\n" + traceback.format_exc() return str (ret)
原理和之前说的一样,这里利用了python的技巧,会更加的方便,后续将会使用这种方式来进行function call。
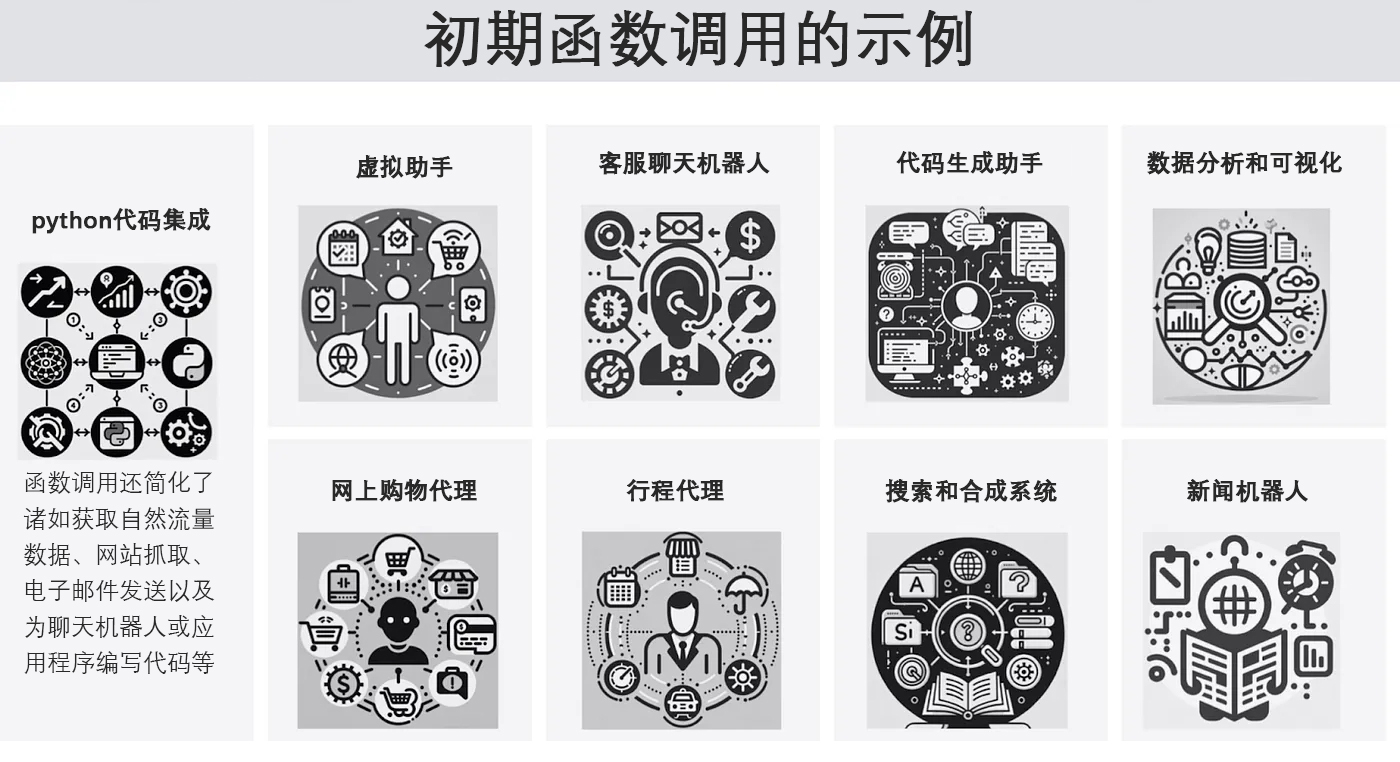
已有的工具调用场景
关于工具调用,目前已经有一些初期的案例:
国内也有一些使用流的Agent构建:
比如百度的baiduAgent ,有点门槛,会玩的还是挺方便:
还有一个说是零代码Agent,我感觉这不算Agent,只能说是特殊的Prompt:
还有字节的扣子 ,感觉和百度这个差不多?
感觉国内发展的还是挺快的,虽然这些工具看起来不太精细。
LangChain对于ChatGLM3工具调用的支持
LangChain库对工具调用是进行了封装的,但它不能很好的支持ChatGLM3工具调用,需要添加额外的代码才行,最刚开始我看官方文档的时候不太能懂是在干什么,特别是role变来变去的,即便是我按照官方文档下来,后面万一需要个性化的处理我可能就懵逼了,所以这就促使我去了解是如何实现的。这样一个过程下来,后面就算更换为其他大语言模型也能游刃有余。如果一上来就按照LangChain的做法会很容易迷失在源码的海洋中,这种效率会非常低。
在官方文档中有具体的例子,后续在整理到这里。
参考
官方文档 - 工具调用
AI Agent行业报告:框架拆解、应用方向、应用领域及相关公司深度梳理
图片改编自:
LLM Beyond its Core Capabilities as AI Assistants or Agents
Expanding AI Horizons: The Rise of Function Calling in LLMs


 微信打赏
微信打赏