Stable Diffusion本地部署+controlNet插件
参考腾讯云GPU服务器部署Ai绘画Stable Diffusion 小白可用
介绍
Stable Diffusion是2022年发布的支持由文本生成图像的 AI 绘画工具,是一个开源的工具,其他的比如Midjourney、文心一格目前闭源。
现在Stable Diffusion的图形化界面主要用的是越南人AUTOMATIC1111的项目stable-diffusion-webui,里面的代码是尽可能方便的构建环境和下载模型文件,但是对于国内的来说就反而变得不方便了,封装的有点过头。我尝试运行bash webui.sh文件或者github仓库硬是下载不了,而且目前大部分的教程都是在教怎么一键运行,包括更改连接之类的,我这儿试了总是有一些文件下载不了,于是决定拆解代码自己取下载和拉取仓库,按照下面的步骤执行就可以知道哪些地方缺东西了:
构建环境
构建conda环境
1 | conda create -n SD python=3.10 |
下载WebUI
下载常用的WebUI
1 | # 这里使用镜像 |
调整代码,打开launch.py,将下面的代码注释掉(这段代码是建立虚拟环境,安装相应的包):
1 | # with launch_utils.startup_timer.subcategory("prepare environment"): |
拉取github:
1 | # 进入到repositories文件夹 |
安装包:
1 | # 回到文件夹 |
下载模型
下载用来生成图片的模型,现在模型有很多,这里先测试能不能用,就先下载这些模型,每一个模型大概有4G的占用。
1 | # =================== 下载用来生成图片的模型 =========== |
其他模型,这些模型可以在civitai找到:
- chilloutmix:网上看到比较火的模型,包含有18+的内容!
- Korean-doll:可以绘制韩风美女。
- Lora:现在好像找不到了,包含有18+的内容!
- WAI-REAL_CN:中国风美女!
下载了之后把模型文件放在
models/Stable-diffusion下面,就可以选择这个模型了。
下载clip模型,这个给图片和提示词建立关联用的东西:
1 | # 进入https://huggingface.co/openai/clip-vit-large-patch14/tree/main |
脸部优化:
1 | # https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.4.pth |
开始运行
1 | # --listen 以0.0.0.0侦听 |
运行成功后显示:
1 | Loading weights [6ce0161689] from /home/xxx/stable-diffusion-webui/models/Stable-diffusion/v1-5-pruned-emaonly.safetensors |
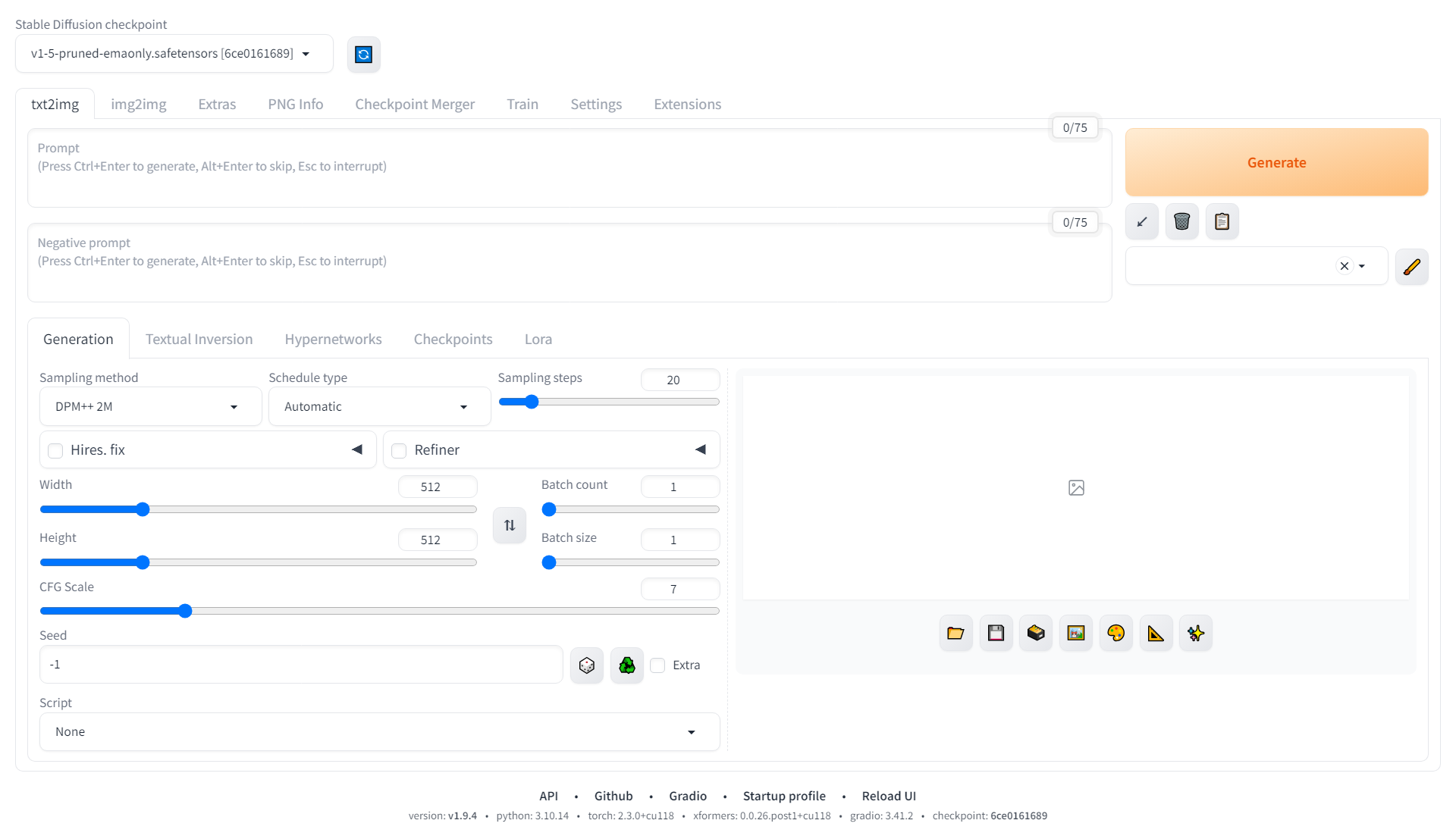
WebUI的界面,左上角可以选择模型,中间可以选择模式,右下角是模型参数,右侧是显示生成的图片。
如果运出现下面两种错误:
AttributeError: __config__AttributeError: 'NoneType' object has no attribute '_id'解决办法[Bug]: AttributeError: config:
2
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fastapi==0.90.1
写的prompt:
1 | A mouse floating in outer space, sitting on Tom's head and hugging a piece of cheese. |
生成的图:

试了一下,原本下载的模型v1-5-pruned-emaonly.safetensors生成的结果惨不忍睹。prompt这么短都给我省略内容是吧!我的汤姆猫呢!
运行过程中,显存大概占用6G左右。3090完全够用!
ControlNet
controlNet的插件安装和使用后续再补充。
 微信打赏
微信打赏